LLaVA
Visual Instruction Tuning. (NeurIPS 2023)
背景与动机
在本文之前,无论是传统意义上的“大”模型,还是现在提及的大(语言)模型(LLM),都已经有了广泛的研究。
例如多模态学习(MM)通过结合计算机视觉和自然语言处理知识在诸如图像-文本检索(Image-Text Retrieval)、图像描述(Image Captioning)和视觉问答(Visual Question Answering)等。
在LLM出现之后,人们发现现有模型已经具备可观的指令遵循的能力(给定指令后,让LLM能够按照指令的描述完成特定任务),例如训练指令遵循的Agent去完成一系列任务和指令微调后让LLM能够在特定领域按照人类的要求完成任务。
然而,结合LLM和MM的研究相对还较少,一是因为目前的LLM还是以文本为核心的模型,如何将视觉信息嵌入进语言模型中还有较大的研究空间;二是视觉语言指令微调数据集(Vision-Language)还较缺乏,因为与CLIP这种图像-文本对的收集方式不同,要得到可信的指令微调数据集是有难度的。
为此,本文的工作可以简单总结为以下两个:
- 通过ChatGPT和GPT4构建了一个具备一定规模的多模态指令微调数据集。具体构建方式见后文,但可以预想的是,文本之所以选择这两个模型辅助数据集的构建,一是纯人工的构建必然花费大量的成本,二是这两个模型经过很好的人工反馈强化学习(如InstructGPT)的训练,给出的回复一定程度上更贴近人类的偏好。
- 利用CLIP作为视觉特征的编码器,利用一个包含大量ChatGPT回复的数据集上微调的LLaMA模型Vicuna作为LLM,从而形成了一个多模态大模型:LLaVA。
数据集构建
LLaVA数据集构建的核心是利用GPT辅助生成视觉指令数据。
传统的多模态数据缺乏指令相关的内容,以文本内容较为丰富的image caption相关的数据集为例,其数据构成一般是$X_v: X_c$,既对于每一个图像样本$X_v$而言,都有对应地描述图像内容的文本$X_c$。
在本文中,为了得到指令数据集,作者则利用GPT-4,针对上述提到的$X_c$,让GPT提出可能的问题,也就是假设已经有答案的情况下,让GPT问出符合该答案的问题。假设问题的表示为$X_q$,那么就可以创造出如下格式的指令数据: $X_qX_v$<STOP> Assistant: $X_c$<STOP>。具体的设计方式如图1所示,即给定GPT要求后,收集其产生的回复,从而拼接成固定格式的指令数据。

然而,仅仅使用这种方式产生的指令数据不仅缺乏多样性,还无法提供更复杂和深层次的逻辑推理信息。因此,本文以人工标注的具备高质量目标检测和描述信息的多模态数据集COCO为基础,充分使用数据集中的描述信息captions和目标位置信息bounding boxes来完成多模态指令数据的生成。
具体来说,本文希望GPT基于这两类注释和对应的图像,生成三类核心指令数据:
- 对话数据:设计一个助手和人对话的场景,产生出助手在看图片,并回答人提出的问题,其实就是我们直观能够理解的多模态对话场景;
- 详细描述:为了包含对图像全面和丰富的描述,本文创建了和该类问题相关的一系列问题,并通过询问GPT来产生详细的回复(简单理解就是让GPT对
captions进行扩充) - 复杂推理:上面两类数据重点在描述图像内容本身,为了促进模型的推理能力,本文还创建了很多具备推理要求的问题,从而获得推理指令数据(其实也就是让GPT根据问题生成带推理信息的回复)
基于COCO两类注释得到三类指令数据的大致方式可以见图2:

简单来讲,本文就是基于COCO的图像描述和目标位置信息,针对对话、描述和推理三类任务,人工先设计了多个对应的问题(作为few-shot)来询问GPT,从而让GPT完成对应的回复,以及自行产生问题和回复。
最后,本文收集了158K的不同的语言-图像指令数据集,其中包括58K的对话数据,23K的详细描述数据和77K的复杂推理数据。本文还发现,使用GPT-4产生的数据质量比ChatGPT要好,比如空间推理问题。
任务与方法
本文要解决的任务就是在给定图像的情况下,模型能够根据用户给出的文本指令,准确地进行回复。当然并非必须问和图像相关的问题,毕竟模型核心还是语言模型,但该任务重点强调的是在用户询问和图像内容相关的问题时,模型可以理解并生成对应的回复。这在传统的语言模型、多模态模型和纯文本的LLM上是难以做到的。
模型结构
LLM本身不是问题,因为现有的开源大模型以及在不同数据集上微调过的大模型都种类繁多,因此本文模型结构的设计重点就在于如何将图像信息提供给大模型。本文使用Vicuna为LLM,既图3中的$\oint$,而图像编码是CLIP(使用ViT-L/14)。
总的步骤是:对于提供的图像$X_v$,使用CLIP编码成为$Z_v = CLIP(X_v)$,之后再使用一个简单的线性层将其投影到和文本特征$H_q $一致的维度上,即:$H_v = W\cdot Z_v$,之后将两者拼接起来输入给大模型$H = [H_v;H_q]$。
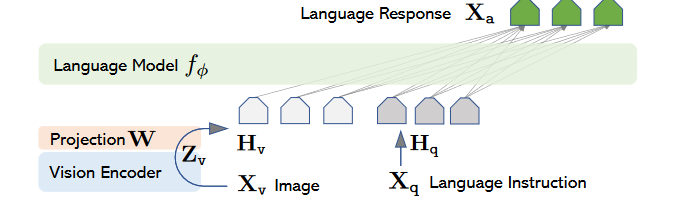
需要注意的是,图像特征并没有直接使用CLIP的输出,而是分别验证了CLIP最后一层Transformer Layer之前和之后的特征;以及所谓线性层也确实非常简单,就是一个维度的变换而已。
模型训练
为了有效地完成多模态的训练,论文采取了两阶段的训练策略。在正式训练之前,对于每张图像$X_v$,会以多轮对话的形式产生训练数据:$(X_q^1, X_a^1, …, X_q^T, X_a^T)$,$T$是总的对话轮次数。简单来说,就是对每个多轮对话的指令$X_{inst}^t$而言,如果是多轮对话中的第一轮,就随机从$[X_q^1, X_v]$或者$[X_v, X_q^1]$中选一个当第一个样本,而之后的轮次则选择依次选择$X_q^t$。看起来略微有点复杂,其实就是刚提问时的指令为问题+图像的组合,而后的指令就是普通问题,根据图4可知,就是针对某个图像做的多次问答而已。

图中的绿色部分的token是用来计算LM损失的,其中<STOP>在实际的训练中以###代替。
有了基本的训练格式,重点就是LLaVA的两阶段训练的详细步骤了:
第一阶段——特征对齐预训练:
-
如果直接进行端到端的训练,理论上会因为图像编码器、全连接层和LLM之间的特征差距导致整个模型无法有效收敛。为此,先将LLM和视觉编码冻住,也就是这个阶段只训练全连接层。
-
训练时,从CC3M数据中筛选了595K的图像-文本对数据,并按照单轮对话的方式,以上面一样的GPT产生指令数据的方式让图像-文本对数据变成指令-回答形式的数据。
-
接着单轮对话的指令数据输入,然后根据LLM的生成情况来更新全连接层的梯度,从而完成特征对齐预训练过程。注意这里用的CC3M数据集不是上文提到的COCO数据集,与之相比,CC3M的文本描述更多的是来自网络,虽然质量不如人工标注,但是具备更好的多样性特定。
第二阶段——端到端微调:
- 该阶段依旧不更新视觉编码特征,而是对LLM和全连接层进行端到端的微调。训练时,根据三种不同回复类型的特点(对话、描述和推理),只有对话是多轮的,而其他两个还是按照单轮对话的方式给数据。既然有单轮和多轮的训练方式,不难想到LLaVA其实是以多模态的一个聊天机器人的形式提供的。
- 此外,为了证明模型和方法的有效性,论文还在ScienceQA数据集上做了评估。ScienceQA本身就是一个具备图文信息的科学问答数据集。
结果分析
模型在8张A100显卡上进行训练,超参数设置和Vicuna(v0)一致。在第一阶段中,设置为epoch=1, lr=2e-3, batch_size=128,第二阶段微调时,epoch=3, lr=2e-5, batch_size=32。具体评估分为两类:多模态对话和ScienceQA。
多模态对话:
设计这种对话评估的方式(Multimodal Chatbot)是为了更直观地展示和检查LLaVA理解多模态和上下文指令遵循的能力。如图5所示,本文采用了训练集中没有,但GPT-4技术报告中有提到的一个例子来展现其模态理解和指令遵循的能力。

从图5可以观察到,LLaVA无论是多模态理解还是根据用户指令回到对应问题上,都和GPT-4接近,相反的BLIP-2和OpenFlamingo则仅仅完成了图像的描述而已,并没有遵循用户提出的指令。
当然,没有具体的量化指标,光看一张图是难以服众的。因此本文为多模态对话设计了一系列的实验,具体来说,就是分别调用不同的GPT-4对话API,一个API负责生成回复$R_r$,和LLaVA等模型生成的回复$R_p$进行对比,另一个API(也就是另一个GPT-4调用)负责对给定的$(R_r, R_p)$进行打分,打分主要从有用性、相关性、准确性和详细程度进行回复(helpfulness, relevance, accuracy, detail of the responses)。
具体来说,分别有两个评估数据:LLaVA-Bench (COCO):从COCO-Val-2014中随机选择了30个图像, 并生成三种类型的问题共90道题;以及LLaVA-Bench (In the Wild):收集了一组不同的24张图像,共60个问题,重点在于多样性(包含了室内、室外、绘图和草图等)。
最终,在COCO的评估上,本文重点考虑了以相关性分数为参考的消融实验,如表1所示。

而In-the-Wild上则是对比了其他几个模型的相关性情况,如表2所示。

ScienceQA:
该数据集包含了多个领域共21k的多模态数据(以多项选择题呈现)。为了对比,本文选取了三个主要的baselines,包括:GPT3.5 (text-davinci-002 不使用COT方式)、LLaMA-Adapter和多模态思维链MM-COT(当前的SOTA方法)。
具体评价结果时,本文采用了两种方式,第一种先使用GPT-4预测,当其无法正确回答时,就使用LLaVA来预测,论文发现这种方式和单独使用LLaVA的结果几乎是一致的,说明LLaVA的效果非常不错;第二种则是让GPT-4作为判断标准,当GPT-4和LLaVA得出的答案不一致时,会再次提示GPT-4,让其根据问题+两个不同的答案给出最终的回答。
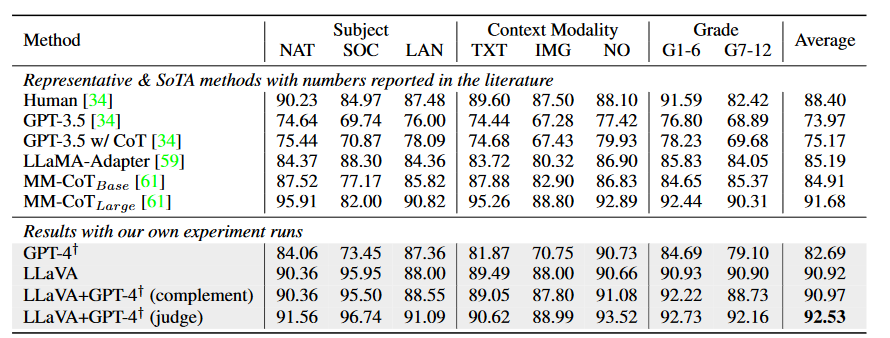
所有提及到的baselines和不同的测试方法所得到的实验结果如表3所示:
消融实验:
这里简单提及消融实验中的重点内容:
- 使用视觉特征时,用的是CLIP的倒数第二层,也就是没有用CLIP的最后一层特征作为视觉特征。在消融中,本文发现倒数第二层的视觉特征性能比直接使用CLIP最后一层的输出要高
0.96%。本文认为这是因为CLIP最后一层的输出更倾向与全局和抽象的图像特征,而前面的层更倾向于图像局部特征。(按照模型的设计,可以理解为让LLM充当全局理解的角色,而视觉编码器最好给出局部信息); - COT的训练方式能够加速模型收敛,也就是加快训练速度,但最后的性能提升其实是有限的;
- 预训练是重要的。本文单独做了无预训练直接学习多模态的实验,结果比有预训练的版本要低
5.11%,说明预训练是非常重要的;(这里的预训练是指第一阶段的特征对齐,不是指LLM和视觉编码器的预训练) - 最后,模型的规模也相对比较重要。本文发现13B的模型表现要稍好于7B的模型。
总结
本文的贡献可以简单总结如下(个人理解):
- 以非常简单的全连接层投影,完成了视觉-文本特征对齐和多模态任务,为后续的多模态大模型提供了更好的范例(简单有效的方法);
- 利用GPT生成了良好可用的多模态指令数据集并公开;
- 充分的实验验证了本文方法的可用性,其两阶段训练的方式有效且符合认知。
LLaVA 1.5
Improved Baselines with Visual Instrction Tuning. (CVPR 2024)
背景与动机
- 待续