Improved Baselines with Visual Instrction Tuning. (CVPR 2024)
背景与动机
- 近年来,LLaVA和MiniGPT-4等多模态大模型在视觉指令遵循和视觉推理等任务上取得了不错的成就,后续的一些工作也在持续地扩展和推进预训练数据、指令遵循数据、视觉编码器和语言模型的规模;然而,目前的多模态模型架构和训练数据存在的各种差异,不同模型在不同的benchmark上也各有所长,这使得我们还不清楚实现通用模型的最佳方法是什么。为此,本文提出了一个系统性的研究,基于LLaVA在受控的设置下研究LLM的设计选择,具体来说就是以LLaVA为主,研究输入、模型和数据对多模态大模型的贡献情况;
- 首先,本文在LLaVA的基础上,将视觉投影层替换为了MLP,并结合学术相关的数据来训练模型(这部分主要采用了FLAN系列的结论,即在训练数据中增加学术类任务的数据对指令微调很有用,能够增强模型的泛化能力)。与其他的模型相比,本文的模型结构只需要相比较少的训练数据和训练时间就能够取得很好的结果(600K的Image-Text Pairs, 在8卡A100上训练一天时间),而其他的一些方法则需要大量的数据和训练时间;
- 之后,本文对多模态大模型中的一些开放性问题做了探索,包括:1)增加高分辨率的图像数据输入;2)通过子任务去探索他们组合任务的泛化能力;3)数据采样策略对训练和性能的影响;4)细化数据的粒度。
- 总之,本文对如何平衡多模态学习和有效扩展大模型做了一个系统性的研究,并为此提出了新的模型LLaVA-1.5(仅仅是用公开数据),并在11个任务上实现了SOTA。
简单来说:
-
就是作者发现LLaVA虽然相对比较简单,但在学术类任务上表现不好,因为这些任务需要比较短的回答。如果任务类型是回答yes/no,LLaVA更倾向于回答yes。作者认为这主要是LLaVA训练时缺少这样的数据导致的,所以作者后续要在训练数据集中增加相关数据;
-
此外,他们又发现InstructBLIP虽然已经做过学术类任务了(如VQA),但这种Qformer结构的模型容易在VQA上过拟合,对需要较长回复的真实对话场景表现的不好,也就是Qformer架构没有平衡好长-短输出的任务。作者分析认为,1)InstructBLIP在训练时用的是比较简单的prompt,即
Q: {Question}: A: {Answer},没有清楚地指出需要的输出格式,所以大模型容易过拟合短的答案;2)Qformer是为了妥协而诞生的,也就是他不微调LLM本身,那么所使用的LLM能否输出较长文本则受限于Qformer的输出token,但毕竟是一个妥协的产物,能力可能并不理想。因此本文在处理需要短回复的时候,将prompt改成了answer the question using a single word or phrase。不同的prompt格式可见表1。

任务与方法
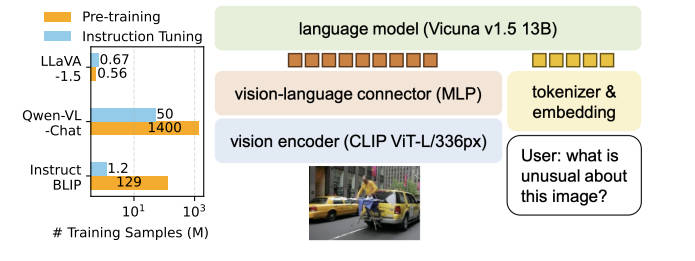
- 其实根据上面的解释就能知道,LLaVA-1.5的核心是增加了学术类数据集,并修改了prompt以增加LLaVA的指令遵循能力。但是考虑到视觉线性投影层太过简单,因此本文将投影层改成了MLP,大致结构如图1所示。
- 在进行后面的工作前,本文先做了一些简单的测试,测试结果如表2。
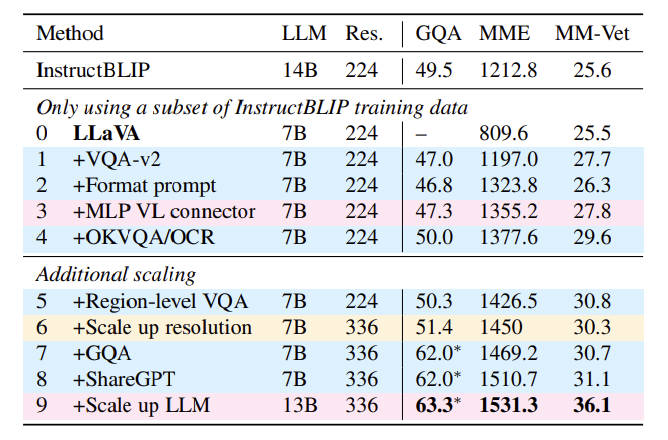
- 可以看到,在GQA、MME和MM-Vet三个数据集上,增加学术数据集、修改prompt格式,替换投影层为MLP,增加OCR能力、增加数据集细节(region-level),提高图像的分辨率等操作,都能够获得比原本LLaVA更好的效果。
- 通过前面初步的验证,知道了提高输入图片的分辨率是有效果的,但CLIP制约了输入图片分辨率最多为
336x336,为了突破这个制约,本文采用了一种相对简单的方法,如图2所示。
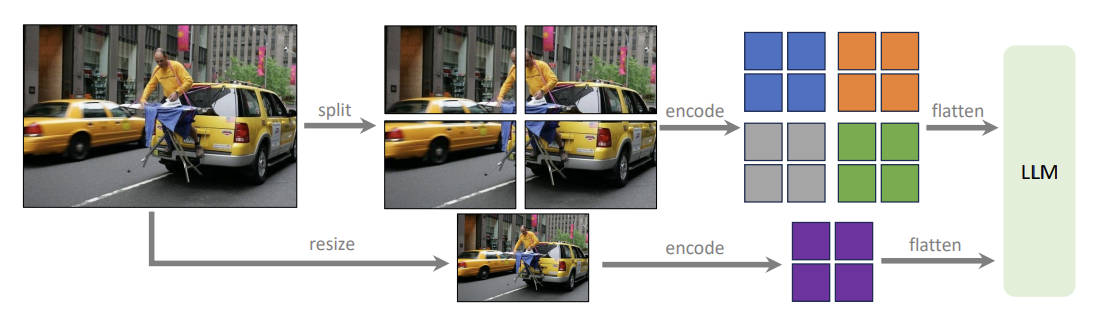
- 根据图2可知,对于高分辨率的图,先进行拆分,也就是变成多张比较小的图,再分别送入visual encoder;为了保留全局的信息,同样也做了resize的操作,将高分辨率的图resize到低分辨率,同样再送入visual encoder。(与标准的LLaVA-1.5不同,通过高分辨率输入训练的模型,本文称之为LLaVA-1.5-HD)
结果与分析
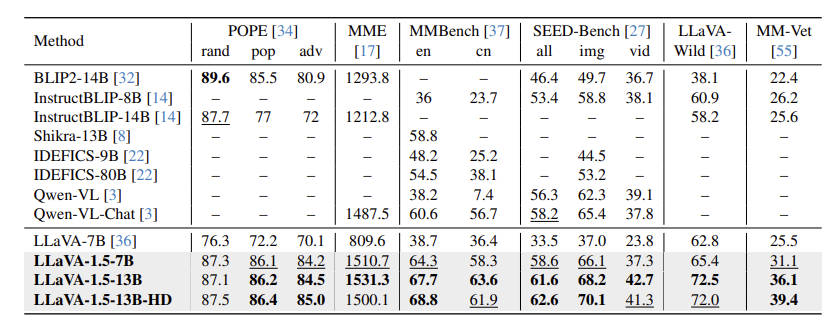
- 本文的实验主要做了两部分,一个是面向学术类的任务,一个是面向指令遵循类的任务。照应上面的说法,可以简单理解为视觉推理时,短输出和长输出的能力。学术类任务见表3,指令遵循类任务见表4。
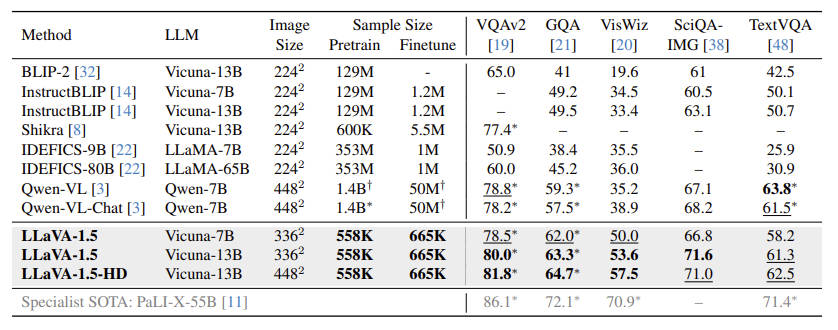
- 可以看到,模型在增加了学术类数据集后,在这类benchmark上的确有更好的性能。而使用更大的模型(7B –> 13B)和提高输入图像的分辨率也的确有更好的效果。当然最重要的是,LLaVA-1.5在预训练和微调时用的数据量相对其他baseline来说是很少的;
-
表4也显示出,在替换模型的投影层后,模型取得了比LLaVA-1.0更好的结果。
-
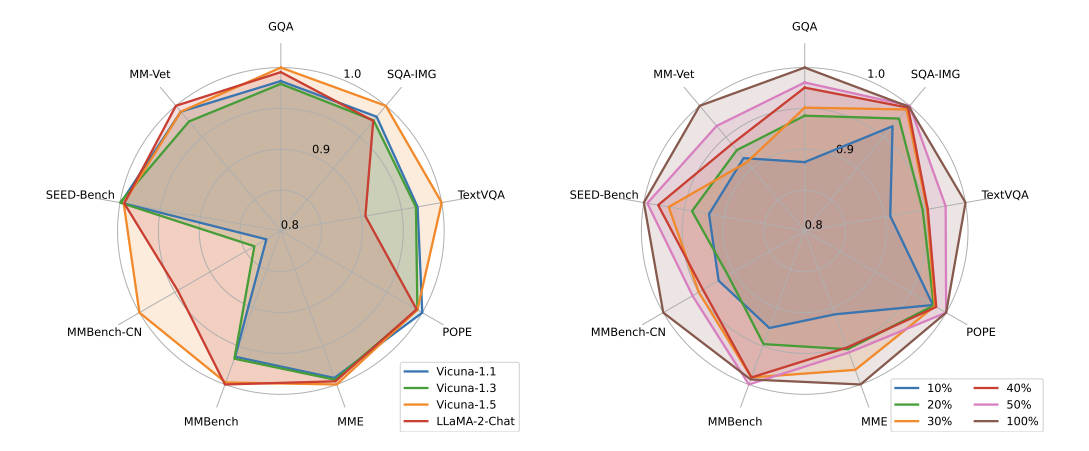
除了主要实验外,本文也对选择什么样的LLM去微调,以及降低数据量会产生什么样的影响做了探索。如图3左边部分所示,是用Vicuna-1.5取得了总体最好的结果,LLaMA-2-Chat次之,而这俩恰好都是基于LLaMA-2进一步微调得到的。虽然LLaMA-2-Chat做了RLHF的训练,但在本文的实验中并不如Vicuna-1.5,作者认为这是因为它的RLHF主要是英文语料,这里的几个benchmark却是多语言的,Vicuna-1.5则基于ShareGPT的数据,拥有较好的多语言数据;
-
在图3右边部分,展现了数据采样的情况,总体效果来说当然是用全数据最好,但即使只采用全数据的50%或40%,模型的总体效果也不是很差,也许未来用较少的数据完成更强的模型也不是不可能。
- 最后,本文还对模型的幻觉及组合任务(即训练A和B任务,但在C任务上的效果,而一般推理C时可由A和B得到)做了简单探索。对幻觉而言,本文一个重要发现是增加图像输入的分辨率有助于减少多模态大模型的幻觉。对这两部分感兴趣的可以自行阅读原文。
总结
(仅代表个人理解和观点)
- LLaVA-1.0擅长对话类推理,但学术类推理(主要是给出较短回复的任务)能力不强,所以单独增加了这部分数据。InstructBLIP虽然也增加了VQA类的数据,但效果并不好,泛化能力大受影响。这是因为Qformer方式不涉及微调LLM本身,其性能受到制约,而且其简单的Q-A形式的prompt也不是很好(本文的猜测),因此对这类较短回复的任务,修改了其prompt。也就是明确告知大模型回答时简单明了地给出答案,不要长篇大论,而常规对话任务则照旧,该说的长一点详细一点的保持正常生成;
- 此外,LLaVA-1.5还增加了一些细粒度数据,并探索了提高输入图像分辨率后的效果。发现输入图像分辨率增加后,模型不仅在benchmark上结果变好,还能减少大模型的幻觉问题。(高分辨率的图像提供更多细节信息);
- 最后,与LLaVA-1.0相比,最直观的差别就是LLaVA-1.5采用了MLP而非单层的线性层来转换视觉特征,虽然这样导致训练时间比1.0的多了一倍,但相对其他模型所采用的大量预训练、微调数据和更长的训练时间而言,LLaVA这种简单的结构依旧能够取得SOTA的结果。