MNRE
-
MNRE: A CHALLENGE MULTIMODAL DATASET FOR NEURAL RELATION EXTRACTION WITH VISUAL EVIDENCE IN SOCIAL MEDIA POSTS. (ICME 2021) (后续简称为 MNRE)
-
Multimodal Relation Extraction with Efficient Graph Alignment. (ACM MM 2021) (后续简称为 MEGA)
背景与动机
关系抽取任务,就是给定文本和实体后,抽取出实体之间的关系。
MNRE这篇论文认为,现有的关系抽取任务都主要基于新闻类的数据,这些数据组织良好,形式正规,相对来说更容易建模。
但对于社交媒体类的数据,这些方法会出现较大的性能下降。这是因为社交媒体的文本内容本身就可能不完整,人们往往会配合图片一起发文,所以在进行关系抽取时,还需要额外对图像的内容进行理解。

如图1-1所示,对于文本JFK and Obama at Harvard @Harvard,可以得到三个实体:JFK、Obama和Harvard,如果不考虑图像信息,可能会错误地得到<JFK, Residence(住在), Harvard>和<JFK, Spouse(配偶), Obama>这些关系。
但如果同时根据图像信息进行理解,就会得到<JFK, Graduated at, Harvard>,因为JFK戴着学位帽,穿着学位服,因此根据文本信息,更容易判断出他毕业于哈佛。
为此,MNRE提出了一个新的任务:多模态关系抽取(MRE,或者MMRE),并为此构建了数据集MNRE(Multimodal dataset for Neural Relation Extraction),该数据集主要由Twitter-15和Twitter-17构建而来,因此是偏向于社交媒体关系抽取的。作者认为,该工作既推动了多模态关系抽取任务的发展,也为对齐较细粒度的文本-图像信息做出了贡献。
第2篇论文是同一批作者,主要是对该数据集做了一些改进,对新数据集做了几个baseline,并验证了自己的方法,具体内容将在后续介绍。
数据集构建
数据集来源:两个多模态实体识别数据集:Twitter-15和Twitter-17,以及部分从Twitter上爬取的内容(2019年1月-2月的内容);
数据集涵盖:没有特意挑选具体的领域,比如运动、社会事件,而是尽可能确保实体的多样性,并且去除了非英语以及实体数量低于两个的句子;
标注方法:源数据、预训练好的NER标注工具、人工标注;
具体情况见表1-1所示,其中
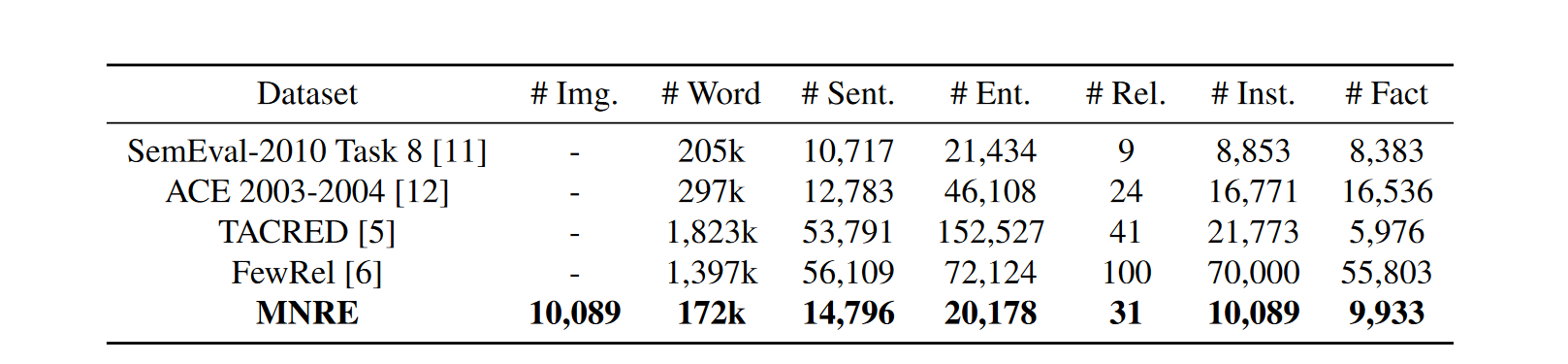
第2篇论文对此做了改进,新的数据信息见表1-2和图1-2。由于后续的大量研究都是基于新数据集的,所以MNRE论文后续的方法和内容将不再介绍,而是以第2篇论文MEGA为主。
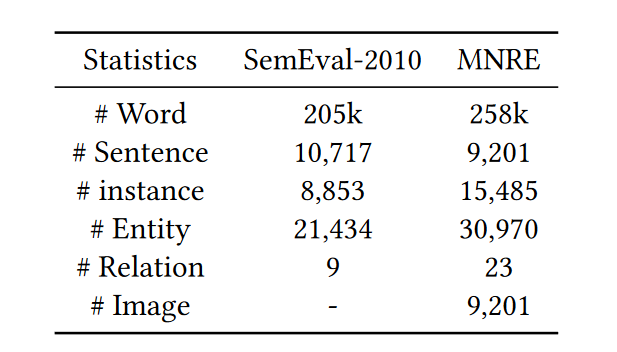
图1-2则是对修改后的数据集的关系类别进行了统计,可以看到关系类别的标签还是存在很明显的不平衡问题。
任务与方法
任务定义非常简单,与文本不同的在于,给定的输入还多了与文本相关联的图片:
$F(e_1, e_2, S, V) \rightarrow Y$,既给定句子$S = (w_1, w_2, …, w_n)$,句子中的实体$e_1, e_2$,以及与句子相关联的视觉内容$V = (v_1, v_2, …, v_n)$,然后预测出实体$e_1,e_2$之间的关系类别$Y$。(注意,虽然定义中给出的是视觉内容集合,但实际数据集中基本上是一个句子对应一张图像,即使有多个关联情况,数据集也是将其划分为多个样本的)
为了构建baseline以做对比,MNRE论文分别测试了三类方法:基于CNN的方法Glove+CNN、基于预训练语言模型的方法BertNER、远程监督的方法PCNN,此外,论文还将CNN与PLM结合了一下,即Bert+CNN的方法。而MEGA保留了Glove+CNN和PCNN的方法,并有专门面向关系抽的预训练Bert模型MTB (Matching the Blanks)、BERT结合场景图的方法Bert+SG、以及额外增加了注意力机制的方法Bert+SG+Att。
MEGA的方法如图1-3所示:
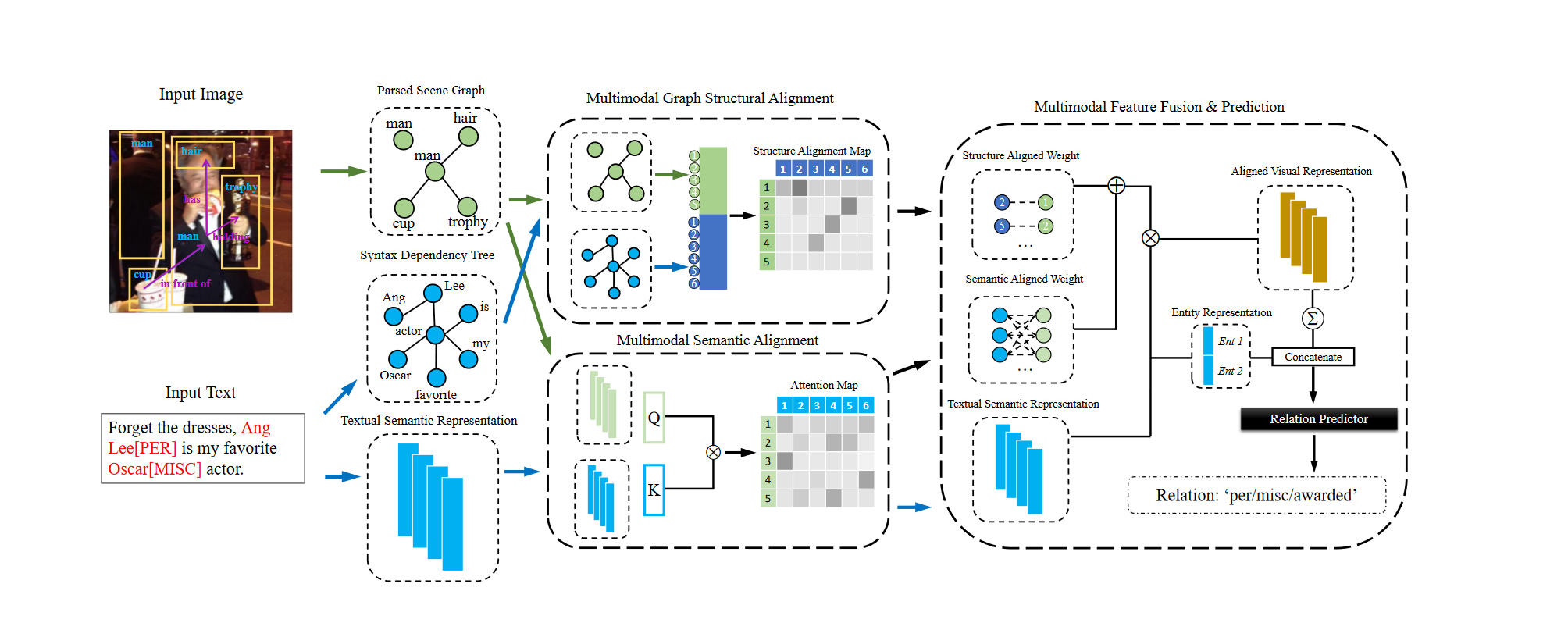
根据方法图,MEGA的方法大致可以分为三部分:结构化特征表示、多模态特征对齐和实体表示与关系预测。
-
结构化特征表示:
文本结构:依存句法树,MEGA使用ELMo提取给定文本得句法,构建出对应的句法树;
图像结构:场景图生成(SGG),MEGA使用场景图生成模型得到针对图像的graph结构信息(场景图就是从图像中抽取出的以 object-relation-object结构为主的Graph)
从模型结构中可以看到,句法树其实就是文本的图结构,场景图就是图像中物体关系的结构,并且该方法额外还是用了文本的表示,也就是$BERT(Text)$;
-
多模态特征对齐:
结构对齐:即对句法树和场景图进行对齐,通过邻接矩阵构建出各实体和目标之间的映射关系;
语义对齐:将场景图的信息和从BERT中出来的文本特征进行融合,简单来说就是一个注意力机制,其中Query和Value是文本特征,Key是图像特征;
-
关系预测:
这部分就是图1-3中的最右边的操作,简单来说,就是将之前结构、语义对齐的视觉特征融合,得到最终对齐的视觉语义特征;以及从BERT中出来的文本特征中得到头、尾实体的特征,将他们做个简单的拼接操作,也就是实体$E_{entity} = [head;tail]$,与对齐的视觉特征$E_{visual}$ 做拼接$z = [E_{entity};E_{visual}]$,然后直接全连接预测关系$output = MLP(z)$
结果分析
MEGA的实验结果如表1-3所示:
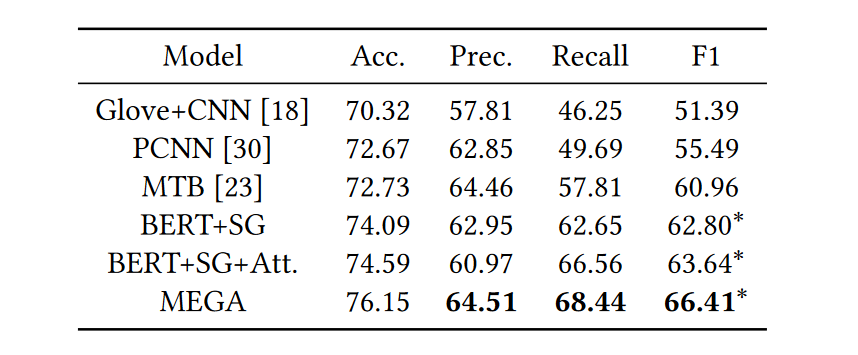
可以看到MEGA是有效的。
直观上来看,MEGA处理多模态信息时,分别从结构对齐和语义对齐两个方向出发,并进行模态融合,这是常见且有效的一种方法。
然而,这种方法并非端到端的,场景图生成是有错误的,句法分析也是有错误的,除非MNRE数据集同时有这两个模型的强监督信号,并且在反向传播时也能更新他们的梯度,否则会由于错误积累导致后面模型性能存在不可能太高的上限。
实际上,哪怕直接利用BERT+ViT的方式进行端到端学习,也能得到比当前结果高的多的性能,甚至不使用视觉信号,BERT也能发挥很好的效果,因此一定程度上需要验证该方法对齐方式的有效性(这也符合对错误累积问题的分析)
此外,其实数据集本身还存在问题,这些将在后续的论文更新中总结。
MORE
MORE: A Multimodal Object-Entity Relation Extraction Dataset with a Benchmark Evaluation. (ACM MM 2023)
背景与动机
前面MNRE数据集率先提出了多模态关系抽取任务(MRE|MMRE),其任务目标是给定文本、对应图片和文本中的实体对后,预测出实体对的关系信息。该任务定义有几个比较强的假设,一是图像-文本是匹配的,也就是图像信息能帮助对应文本的内容理解,二是实体都出现在文本中,虽然不排除图像信息有与之对应的内容,但必须确保文本中含有两个及以上的实体。
对于第一点,对多模态任务而言是非常合理的,但对数据集的质量有要求。
针对第二点,本文则认为相对来说是不合理的,多模态的关系三元组构成元素很多都来自于不同的模态,比如某个实体来源于文本,而另一个则是图像中的物体。为此,本文就设计了新的多模态关系抽取任务形式,即给定文本和对应图像,需要对来源于 文本中的实体 和 图像中的物体 所构成的Object-Entity Pair预测关系,具体如图2-1所示。

也就是说,给定文本和对应图像后,还会从文本中给定若干实体,以及从图像中给定若干物体,最后要求模型对两两的实体-物体组合(Object-Entity Pair)预测出他们之间的关系。为此,本文按照这种任务的形式构建了新的数据集MORE(Multimodal Object-Entity Relation Extraction)
数据集构建
数据集来源:与MNRE数据集从社交媒体推文中收集不同,该数据集从更正规的新闻媒体(The New York Times English和Yahoo News)中收集,因此数据集的质量相对更有保障,而且图-文匹配的程度更高。
MORE的数据集构建分为三个步骤:
- 利用AllenNLP NER工具对文本中的实体进行抽取;利用YoLo V5对图像中的物体进行抽取;随后由人工对抽取的实体与物体进行筛选和过滤;
- 让人工标注者对实体-物体之间的关系进行标注,没有关系的数据标注为
none关系,当然还有很多分组等确保标注质量、偏见和差距的方法,这里就不提了; - 关系过滤,也就是确保只有需要同时根据文本和图像才能得到的关系(过滤掉单独从文本或者单独从图像就能推测出关系的样本)
最终的数据集概要如表2-1:
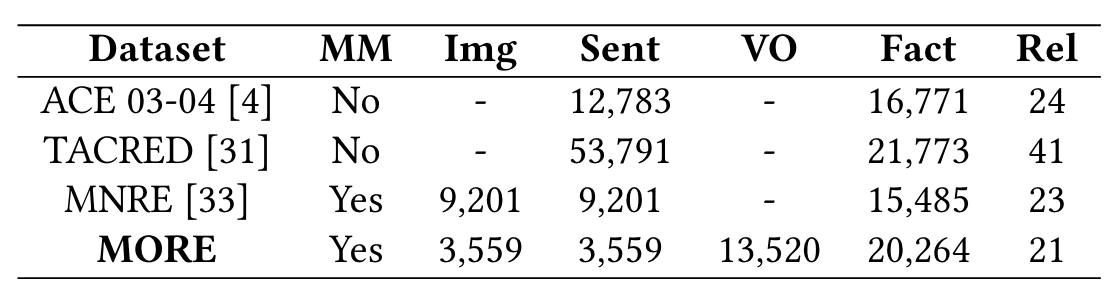
可以看到该数据集也与MNRE数据集做了对比,相比之下,MORE的样本数量变少了,但是关系三元组变多了,并且因为新增的Object任务模式(平均每张图有3.8个object,此外,平均每个文本1.5个entity),MORE数据集更难。进一步地,MORE数据集有22.2%的关系Fact是只包含1个实体和1个物体的,而77.8%的关系Fact含有多个实体和物体,所以对MMRE模型有更大的挑战性。
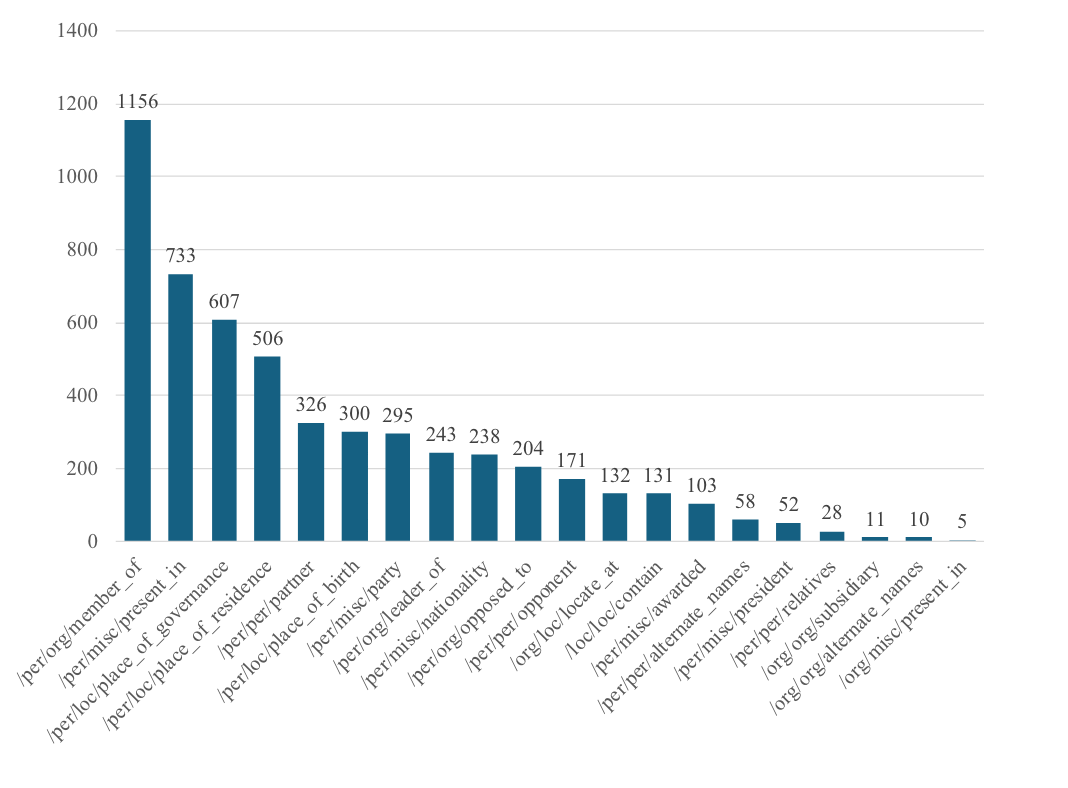
在关系类别的分布上,大致涵盖了生活、位置等领域,但也呈现标签分布不均衡的问题,具体如图2-2所示。
任务与方法
与MNRE的任务定义类似,MORE定义的任务形式为:$F = (e, o, S, V) \rightarrow R$,其中$e \in S, o \in V$。
因为是23年的论文,因此除了较为简单的baseline外,本文还用了一些VLP的模型,后续会列出其性能的比较。
本文提出的方法为MOREformer,模型结构如图2-3所示。
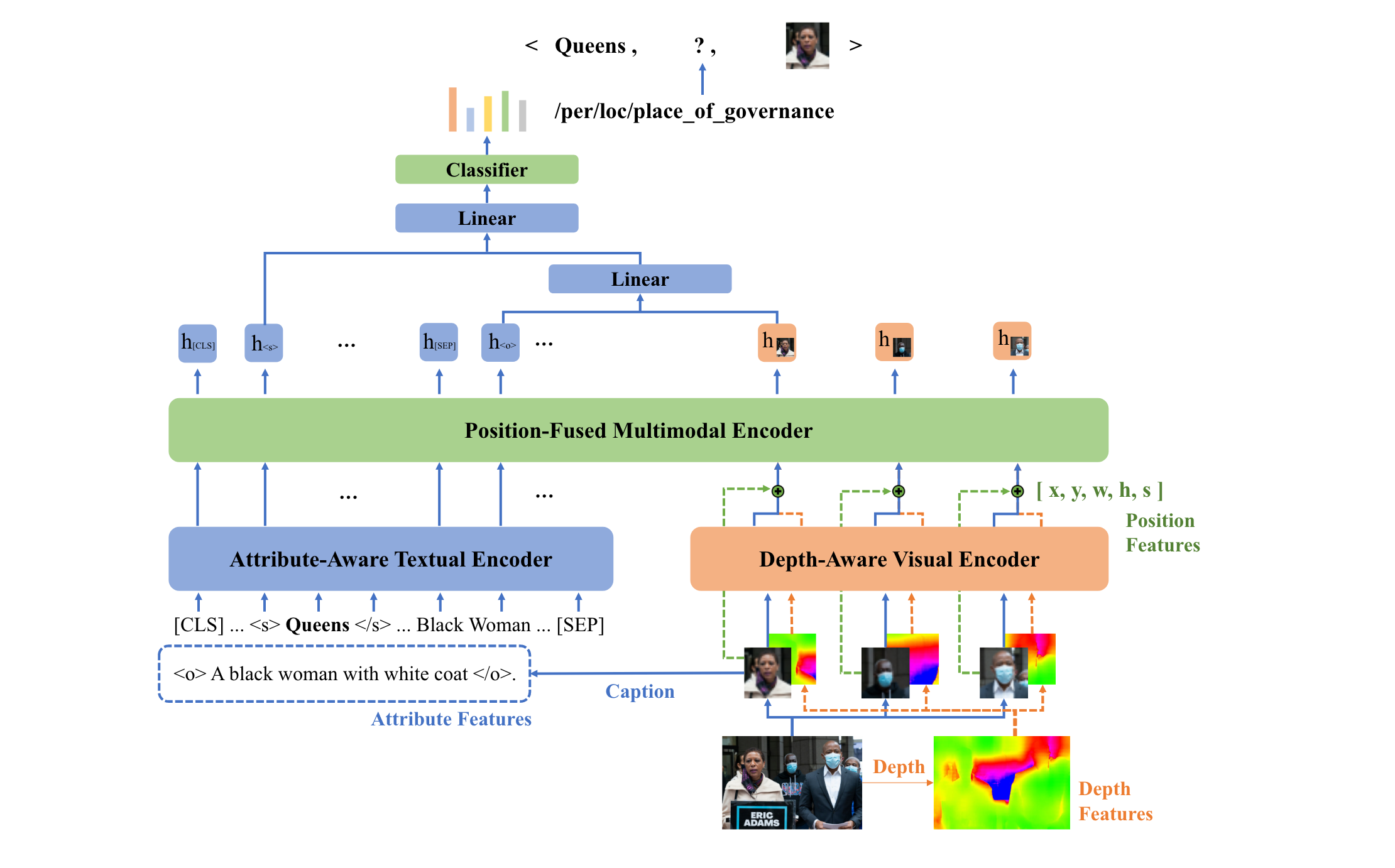
论文提到自己的方法主要是基于MKGformer而设计的,因此先介绍MKGformer的基本方法:其使用的文本编码器是BERT,图像编码器是ViT,对于得到的特征,需要进行融合:
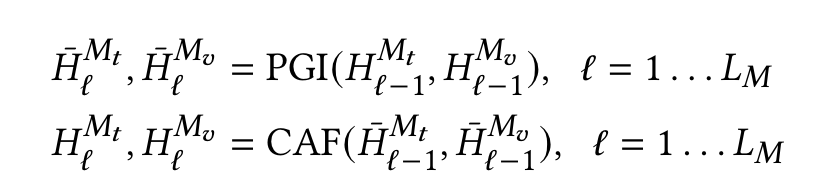
根据公式可以看到,对于文本和图像的特征表示$H^{M_t}, H^{M_v}$,将会被放到前缀指导交互模块(PGI, Prefix Guided Interaction)中,从而得到下一层的特征$\bar{H}_l^{M_t}, \bar{H}_l^{M_v}$,而新的两个特征又会放到相关性融合模块(CAF,Correlation-Aware Fusion)中进行融合。
那么,PGI到底是干什么的?其实就是个注意力机制,而且是个专门处理[CLS] token的模块。对于文本特征而言,就是自注意力机制$M_t[CLS] = Attn(Q_t, K_t, V_t)$,但视觉的前缀则是修改后的注意力,大致为$M_v[CLS] = Attn(Q_v, [K_v, K_t], [V_v, V_t])$,也就是Key和Value是图像与文本的特征拼接,IFAformer也是这种融合的注意力机制。通过PGI,将加强文本[CLS]对自己全局信息的概括能力,以及图像[CLS]对文本-图像全局信息的概括能力。
而CAF模块则负责模态的融合,具体细节后续整理MKGformer时再列出,大致可以认为该模块就是让文本的token和图像的patch进行交互,最后再送入FFN中。
本文以上述方法为基础,主要设计了三个模块:
-
属性相关的文本编码器(Attribute-Aware Textual Encoder):这里不需要看公式,根据图2-3可知,就是一个图像描述生成任务的利用,先利用ClipCap生成图像的文本描述,再将该文本描述作为样本中的文本的辅助信息。这样做也是非常常见的一种方法,因为生成的文本本身就是对图像大致内容的描述,分析该文本有助于模型更好地理解图像信息(当然Image Caption模型的好坏会制约生成文本的作用);具体使用时,本方法则是将整个描述文本当作object来用。也就是说:对于文本$S$和其中的实体$e$,得到BERT分词后的token序列,并将图像生成的描述$caption$拼接上去,之后就是正常通过BERT得到嵌入表示了,即:
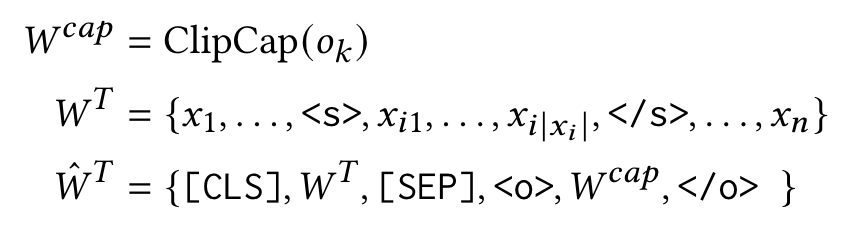
-
深度相关的视觉编码器(Depth-Aware Visual Encoder):图像的深度信息能过表示图中各物体的层次结构,本文利用S2RDepthNet得到图像的深度信息,简而言之就是将ViT得到RGB-3通道的patch和深度网络模型得到的深度表示拼接在一起,形成具有深度信息的图像表示;
-
位置融合的多模态编码器(Position-Fused Multimodal Encoder):这里的步骤比较多,简单来讲就是既要利用图像表示、文本表示,还要使用目标的位置信息(因为抽取的图像是标注出来的,因此数据集中含有目标框bbox信息),从而在最后进行MLP关系预测时,能即考虑文本、图像的特征,还考虑实体、图像层次和目标位置的信息,最终做出预测。
结果分析
本文在实验上做的还是比较充分的,主要的实验结果以及针对本文方法的消融实验分别如图2-4和图2-5所示。
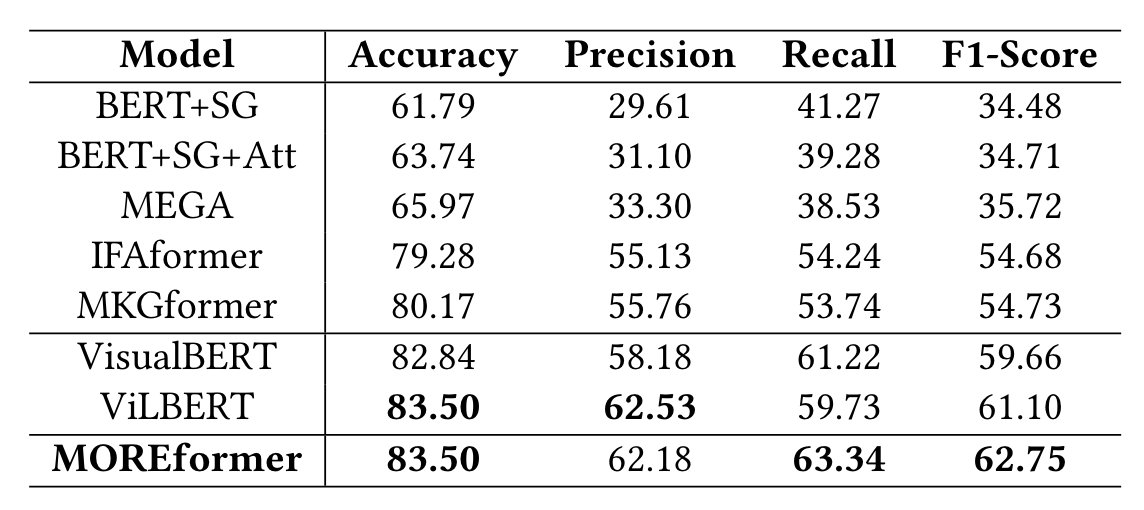
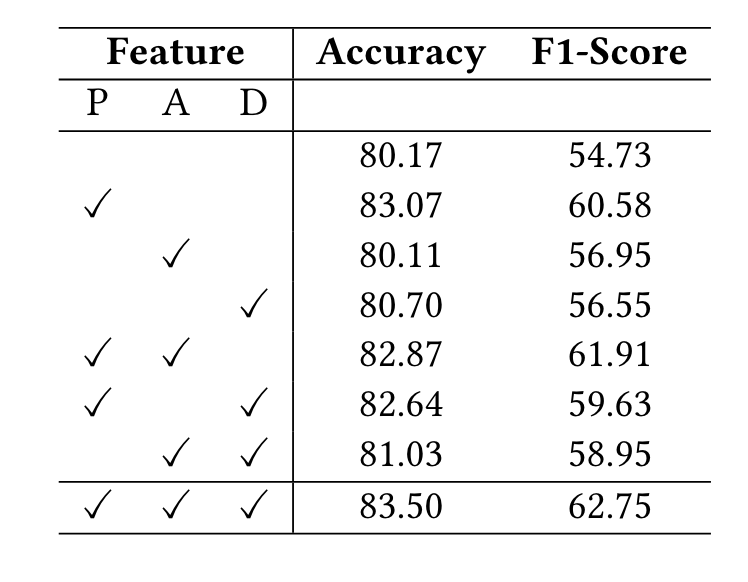
主实验就不说了,主要看看消融实验,其中P、A和D分别指位置融合、属性(描述文本)和深度信息,按照其结果来看,位置信息最重要,其次是对图像的文本描述,最后是深度信息。这说明文本模块(BERT)发挥了更大的作用,而图像模块(ViT)需要更细致的信息才能起作用。
其次,和MNRE那里类似,本文也用了很多属于pipeline的模块,例如深度信息生成和图像描述生成,这些模型都没接受梯度更新,因此他们的错误会累积到后续的模块中去。