ViT
An Image is worth 16x16 Words: Transformers for Image Recognition at Scale. (ICLR 2021)
Abs. & Int.
-
首先,Transformer在NLP已经很普遍了,并且得到了很大的进步(无论是数据还是模型参数),而CV这边尝试的大多是让自注意力和CNN进行配合;
然而,如果让每个像素点都参与到SA的计算中来,将是无法接受的计算开销。因此,有将SA仅仅用作局部的查询的工作,也有让SA分别在不同的块中使用的办法,但这些办法都需要复杂的工程能力才能在硬件加速器上跑起来。和ViT最近似的工作是从输入中提取2x2大小的patch(块),然后使用SA,但这种方式只适合低分辨率的图像,而ViT不仅几乎和文本Transformer一样,还能处理中等分辨率的图像,并能达到或超过CNN的性能;
-
本文希望能够参考transformer,尽可能做少的修改,让其像处理文本一样处理图像信息,以利用transformer的计算效率特性和扩展性;
Transformer原文中说,对于每一层的计算复杂度,SA和CNN分别是$O(n^2·d)$和$O(k·n·d^2)$,因为n往往都比d小,所以SA是比CNN更高效的;
-
因此,本文将图像拆成patch,这个patch可以看成是NLP那边的token一样;
-
本文发现,在中等的图像数据集ImageNet上,不经过正则化,得到的模型比ResNet要低几个点,这主要是因为transformer没有CNN的两个归纳性偏好:平移不变性和局部性;
-
但在继续增大训练数据的规模后(从14M扩大到300M),Visual-Transformer的性能在逐步增加,并实现SOTA
Model.
文本的Transformer处理的是一维的序列,因此ViT需要先将2D的图像输入也变成类似的。对于一张图片$X \in R^{H \times W \times C}$,其中$(H, W)$为图片的高和宽,而$C$为图像的通道,首先将其展成2D的patch,每个patch的大小为$X_p\in R^{N \times (P^2 · C)}$,这里的$(P, P)$为patch的高和宽,$N$为patch的数量,不难得到$N = HW/P^2$。
根据上面的表示,对于一个224x224x3的图,如果需要patch为16x16x3的分辨率,那么将得到$224^2 / 16^2$,也就是14x14个(共196个)patch。当然,这样来讲也并不容易让人理解,所以直接看部分核心代码的实现(为直观起见,省略并修改了部分代码):
|
|
通过代码可知,利用16x16的卷积核,将原图打成14x14个patch,每个patch的通道维度从3变为768,再Flatten并变维为$(B, N, C)$。具体可看下图的图片输入及Linear Projection部分。
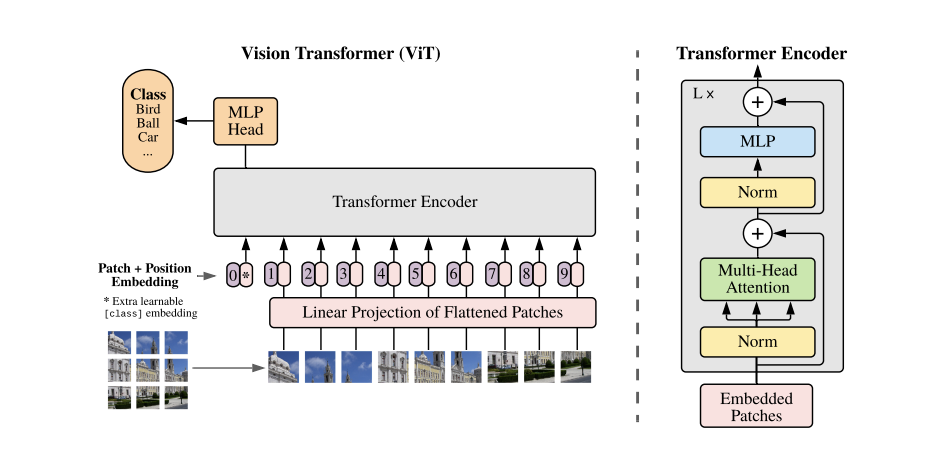
此外,为了和NLP分类任务保持一致,这里也在所有patch前面增加了一个patch,即分类头CLS,因此最终传给Transformer的是$(B, N+1, C)$,在这里的例子中是$(B, 197, 768)$
之后还需要做位置编码,ViT使用的是可训练的1维位置嵌入,shape和$(B, N+1, C)$保持一致,然后直接和每个patch相加。
接着就是具体Transformer Encoder部分,经过LayerNorm之后,shape依旧是$(197, 768)$,在MSA部分,先将输入映射到QKV,假设有12个头,则QKV的shape为$(197, 64)$,输出后再拼接成$(197, 768)$,再经过一层LayerNorm,然后送入MLP。这里MLP的操作也比较简单,完成了:$(197, 768) \rightarrow (197, 3072) \rightarrow (197, 768)$的操作。当然,在每次送入LN层前有一个残差$x + f(x)$的操作。
因为每个block的输入和输出都是$(197, 768)$,因此可以堆叠多个block,最后输出CLS作为分类任务的依据。
具体流程也可以参考下面的公式:
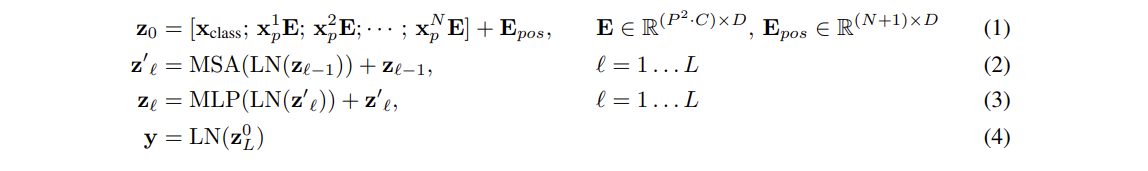
注:
-
这里的位置编码,原文实验显示,无论使用(1, 2, …, N)的1D方式,还是(11, 12, 13, …., )的2D方式,性能差距都不大;也就是没有位置编码和有位置编码会有一定的性能差距,而不同的位置编码方式之间的性能差距则比较小。文中推测这是因为使用的是patch,而非pixel的输入,因此空间之间的信息差异就没那么重要了;
-
考虑到Transformer没有CNN那样的inductive bias,也就是局部性和平移不变性,那么能不能适当的将两者混合一下呢(Hybrid),因此ViT利用Conv2d提取特征图的方式得到了patch,也就是上面代码部分的16x16卷积操作;
-
ViT一般是现在一个很大的数据集上进行预训练,再针对下游任务进行微调(like bert),根据以前的经验,使用比预训练更高分辨率的图片进行微调更有用。需要注意的是,虽然微调增加图片分辨率对Transformer没有影响,但是前期预训练好的位置编码可能就意义不大了,文中推荐采取二维插值的办法;
-
上面提到增加了CLS分类头,那么能否不用它,而是直接对最终的$(196, 768)$做平均,然后进行分类呢?实验证明二者性能也差不多。(那为什么要使用CLS?只是为了和BERT一类的方法保持一致性);
-
位置编码和CLS头可以简单按照下面的方法添加:
1 2self.position_embedding = nn.Parameter(torch.zeros(1, 196+1, 768)) self.class_patch = nn.Parameter(torch.zeros(1, 1, 768))
Exp.
-
数据集上,模型主要用了:ImageNet (1K class, 1.3M image)、ImageNet-21K (21k class, 14M image)和JFT (18k class, 303M 高分辨率image)做预训练,用了CIFAR-10等多个数据集做测试(包括微调和few-shot的方式);
-
模型变体上,base和large和BERT一样,但是ViT扩展了Huge的版本:
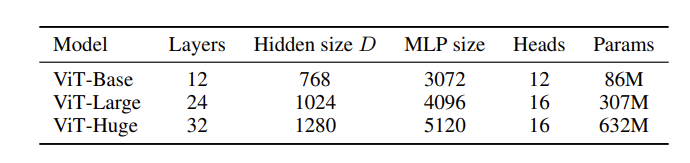
后续的文献和模型应用中,有特定的表示方法,如ViT-L/16表示ViT Large, patch的大小是16x16;
-
比较的baseline主要是两个:BiT(Big Transfer,ResNet-based)和Noisy Student(semi-supervised, EfficientNet-based),他们是下面数据集的SOTA,其中Noisy Student是ImageNet的SOTA,BiT是其他几个的SOTA;具体实验参数是:
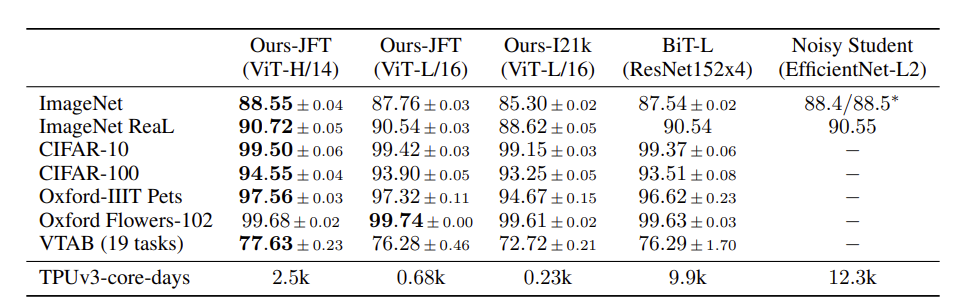
其中TPUv3-core-days表示以:使用一个TPUv3单核训练一天,为标准单位。可以看到,ViT-H/14 要2500个,普通机构是消耗不起的
-
但我们依旧能看到,ViT可以说是全胜,这也证明了开头论文说的继续增大训练数据的规模后,ViT的性能在逐步增加,并实现SOTA; (但是后面也做了实验,实验结果大概是:数据集较小时,建议还是使用ResNet,数据集很大时用ViT来预训练才会有用)
-
ViT的训练时间也变少了(相对两个baseline来说)
Conclu.
- ViT适合用在数据集较大的视觉预训练任务上,如果数据集较小,使用ResNet更合适;
- ViT相对CNN-based的方法,训练更省时间,但预训练的成本依旧是一般机构无法承担的;
- 混合结构Hybrid,即上面代码中利用卷积的方式,而非直接按照图片像素切分成patch,在小模型上表现更好,但随着模型变大,就不如直接切分了(原文中也比较疑惑,因为混合结构应该是兼具二者长处的,个人认为可能是模型大了后,Transformer不再需要inductive bias的帮助,甚至它可能会影响SA的学习,因此模型越大,纯SA的Transformer就更好)
- 当前的ViT主要用在分类任务上,那么还有很多的,如目标检测、分割等任务需要进一步的研究
CLIP
Learning Transferable Visual Models From Natural Language Supervision. (ICML 2021 CCF-A)
Abs. & Int.
先前用于分类的SOTA模型,需要通过对预定义好的类别进行学习,这种方式使得这类模型的通用性和扩展性不好,因此一旦需要预测新的类别时,就需要额外的标注数据进行训练。那么,通过直接从文本中学习图像也许可以是一种更节省更直观的替代方案。
在NLP任务中,以GPT3为例,通过利用大规模语料进行学习的预训练模型,即使不增加额外数据或只使用很少的数据微调,也能够很好地应用于下游任务。这种利用大量网络语料的方法所产生的效果已经比高质量人工标注数据带来的性能提升更强了。
但是在CV这边,却主要还是依靠人工标注的数据,那么能不能借箭NLP这种方法,使用来自于网络的文本和图像,而不再依靠手工标注的数据呢?
事实上,以前也有很多工作采取了这种方式,但他们依旧不如全监督的模型。这主要的原因在于这些方法所使用的数据的规模太少。